Caracterización básica de variables aleatorias
Existen dos formas de visualizar la función de distribución de una v. a.
- Función de densidad de probabilidad f(x): Función que describe la probabilidad de que una variable aleatoria X asuma un cierto valor xi.
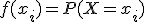
- Función de distribución acumulada F(x): Función que describe la probabilidad de que una variable aleatoria X tenga un valor menor o igual que cierto valor xi.
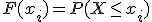
Dada una variable aleatoria, podemos hacer una primera caracterización en base a dos conceptos:
- Esperanza: Valor medio de la v.a.
- Varianza: Dispersión de la v.a. con respecto a su valor medio.
Estos dos conceptos están asociados a la población que constituye la v.a. pero, en general, únicamente disponemos de una muestra de toda la población. Supongamos que disponemos de una muestra de n elementos de la v.a. X = {x1, x2, ..., xn}. En ese caso, se emplean estimadores:
| Estimador de la media | 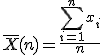 |
| Estimador de la varianza | 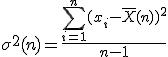 |
Por comodidad y por facilidad de interpretación, es más habitual calcular la raíz cuadrada del estimador de la varianza, lo que nos da la desviación típica o desviación estándar.
Reflexión
¿Son suficientes el estimador de la media y el estimador de la varianza para caracterizar una variable aleatoria? ¿Y si disponemos de la esperanza y varianza poblacionales?
Ejemplos
Supón que has estado midiendo el peso en dos clases de la universidad. En la primera clase los pesos son (90, 70, 91, 69, 80, 89, 72, 68, 70, 90); mientras en la segunda son (81, 80, 79, 78, 79, 82, 75, 85, 75, 75).
Calcula la media y desviación estándar del peso de cada clase. ¿Qué conclusiones sacas?
Obra publicada con Licencia Creative Commons Reconocimiento No comercial Compartir igual 3.0